


Classificação Multirrótulo: Calculando Medidas de Avaliação Parte 1


Matriz de Confusão
Antes de qualquer coisa, precisamos construir uma matriz de confusão multirrótulo. Mas o que é matriz de confusão? Em termos gerais, uma matriz de confusão é uma tabela que nos permite ver o desempenho de um algoritmo de classificação.
Em um problema de classificação simples-rótulo, o algoritmo classifica uma instância em uma classe, isto é, ou aquela instância faz parte daquela classe (categoria) ou não. Vamos usar um exemplo para melhorar o nosso entendimento da coisa toda. Considere que a gente tem um dataset que possui um único rótulo e que pegamos uma parte dele para treinar o modelo e a outra parte para testar.
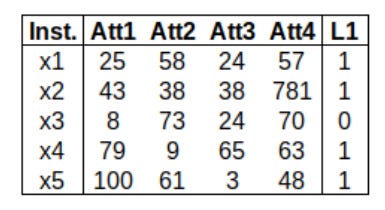
A Figura 1 mostra o conjunto de testes deste dataset ilustrativo. A gente nota que as instâncias x1, x2, x4 e x5 pertencem ao rótulo L1, enquanto a instância x3 não pertence. Agora considere que a predição do classificador para esse conjunto de teste foi a seguinte:
Vamos ver agora quantas predições o classificador acertou? Isto é, vamos ver se o rótulo predito é igual ao rótulo verdadeiro:

O nosso classificador aqui acertou apenas duas predições, que foi para a instância x1 e x5. Como fica então a matriz de confusão? A Figura 2 mostra como podemos montar essa tabela:

Como vocês podem notar, podemos construir a matriz de confusão de várias formas e ela nos fornece as seguintes definições:
- Condição positiva (P): número de casos positivos reais nos dados, isto é, a instância é originalmente positiva para a classe, portanto pertence à classe;
- Condição negativa (N): número de casos negativos reais nos dados, isto é, a instância é originalmente negativa para a classe, portanto não pertence à classe;
- Verdadeiro Positivo (TP = true positive): número de instâncias da classe positiva classificadas corretamente, isto é, a classe é originalmente 1 para a instância e o modelo previu 1;
- Verdadeiro Negativo (TN = true negative): número de instâncias da classe negativa classificadas corretamente, isto é, a classe é originalmente 0 para a instância e o modelo previu 0;
- Falso Positivo (FP = false positive): número de instâncias em que a classe verdadeira é negativa, mas foram classificadas incorretamente, isto é, como se pertencessem à classe positiva, portanto a classe é originalmente 0 para a instância, mas o modelo previu 1;
- Falso Negativo (FN = false negative): número de instâncias originalmente pertencente à classe positiva que foram incorretamente preditas, isto é, como se pertencessem à classe negativa, portanto, a classe é originalmente 1 para a instância, mas o modelo previu 0.
Vamos calcular primeiro os valores de P e N do nosso exemplo:

Pronto, vemos aqui que temos um total de 4 instâncias positivas e 1 negativa para L1, então, P = 4 e N = 1. Originalmente as instâncias x1, x2, x4 e x5 pertencem à classe L1, enquanto x3 não pertence.
Bem, precisamos agora fazer uma verificação nos resultados, calculando o total de valores verdadeiros e falsos, seguindo as regras abaixo, onde L indica o rótulo do dataset. Estou generalizando pois vamos precisar dessas informações mais pra frente quando lidarmos com vários rótulos ao mesmo tempo.
a) True 1 = Se L-V = 1, então L-V’ = 1, senão L-V’=0
b) True 0 = Se L-V = 0, então L-V’ = 1, senão L-V’=0
c) Pred 1 = Se L-P = 1, então L-P’ = 1, senão L-P’=0
d) Pred 0 = Se L-P = 0, então L-P’ = 1, senão L-P’=0
L’ é o resultado dessa verificação. V indica Verdadeiro enquanto P significa Predito. Efetuando o cálculo dessas regras obtemos a seguinte tabela:

L1-V é igual a 1 em quatro instâncias, enquanto L1-V é igual a zero em apenas 1, o que está de acordo com os dados originais. L1-P é igual a 1 em 3 instâncias e igual a 0 em 2. Isso é exatamente igual à soma de 1’s e 0’s que eu fiz na tabela anterior.
No entanto, preciso deixar isso bem explícito pois no caso do multirrótulo fará diferença a forma com que conduzimos esse cálculo. Agora precisamos calcular TP, TN, FP e FN:
a) TP = Se (L-V’ = 1 e L-P’ = 1) então 1, caso contrário 0;
b) TN = Se (L-V’ = 0 e L-P’ = 0) então 1, caso contrário 0;
c) FP = Se (L-P’ = 0 e L-P’ = 1) então 1, caso contrário 0;
d) FN = Se (L-P’ = 1 e L-P’ = 0) então 1, caso contrário 0
Realizando estes cálculos chegamos ao seguinte resultado:

Agora sim temos os valores que realmente nos interessam! Os valores TP = 2, TN = 0, FP = 1 e FN = 2 e são os que comporão a nossa matriz de confusão, da seguinte forma:
E assim terminamos de montar a matriz de confusão para um rótulo! A partir dessa matriz podemos calcular várias coisas. Como eu estou falando aqui para vocês sobre multirrótulo, então, nós vamos repetir esse mesmo processo para um dataset de exemplo multirrótulo. No entanto, isso vai ficar para o próximo artigo! Espero vocês lá.
Este artigo foi escrito por Elaine Cecília Gatto - Cissa e publicado originalmente em Prensa.li.