


Classificação Multirrótulo: Calculando Similaridades entre Rótulos - Parte 13


Olá de novo, galera!!! No artigo anterior vimos como calcular uma medida de similaridade. Hoje vou criar com vocês um código que conseguirá calcular várias medidas de similaridade. Acho que vocês já devem estar suspeitando como fazer isto, não é mesmo? Então, vamos lá.
ATÉ AGORA ...
Antes de ir para o tema principal, vamos recapitular o código que está no script principal.R:

Coloquei cores pra ficar bem fácil de entender. Essa é a execução do nosso código até o momento. Os passos estão listados nos comentários do código e são autoexplicativos. Tudo o que está aí já foi explicado nos artigos anteriores, também.
O que quero mostrar agora é uma automatização de tudo isso aí! Vamos começar nosso estudo de caso colocando o código pra executar 4 medidas de similaridades: vari, russel.rao, jaccard e cosseno.
CALCULANDO VÁRIAS MEDIDAS
Para sermos capazes de executar o mesmo código para várias medidas, basta fazermos um LOOP. Sim, é só isso mesmo mas, veja, não serão executadas ao mesmo tempo. Isso eu vou mostrar depois como você pode fazer. No nosso script similaridades.R existe a seguinte funcão:
# nomes das funções
getNamesListFunctions <- function(){
retorno = list()
names_function = c("ample",
"anderberg",
"baroni.urbani.buser.1",
"baroni.urbani.buser.2",
"braun.blanquet",
"bray.curtis",
"canberra",
"chord",
"cityblock",
"clement",
"cohen",
"cole.1",
"cole.2",
"cole.3",
"cosine",
"czekanowski",
"dennis",
"dibby",
"dice.1",
"dice.2",
"dice.3",
"disperson",
"doolittle",
"driver.kroeber.1",
"driver.kroeber.2",
"euclidean",
"eyraud",
"fager.mcgowan.1",
"fager.mcgowan.2",
"faith",
"fleiss",
"forbes.1",
"forbes.2",
"forbesi",
"fossum",
"gilbert.well",
"goodman.kruskal.1",
"goodman.kruskal.2",
"gower",
"gower.legendre",
"hamann.1",
"hamann.2",
"hamann.3",
"hamming",
"harris",
"hawkins.dotson",
"hellinger",
"inner.product",
"intersection",
"jaccard",
"jonhson",
"kent.foster.1",
"kent.foster.2",
"kuder.richardson",
"kulczynski.1",
"kulczynski.2",
"kulczynski.3",
"kulczynski.4",
"lance.williams",
"loevinger",
"manhattan",
"maxwell.pilliner",
"mcconnaughey",
"mean.manhattan",
"michael",
"minowski",
"mountford.1",
"mountford.2",
"neili",
"ochiai.1",
"ochiai.2",
"ochiai.3",
"otsuka",
"pattern.difference",
"pearson.1",
"pearson.2",
"pearson.3",
"pearson.heron.1",
"pearson.heron.2",
"pearson.heron.3",
"peirce.1",
"peirce.2",
"peirce.3",
"rogers.tanimoto",
"rogot.goldberd",
"russel.rao",
"scott",
"shape.difference",
"simpson",
"size.difference",
"sokal.michener",
"sokal.sneath.1",
"sokal.sneath.2",
"sokal.sneath.3",
"sokal.sneath.4a",
"sokal.sneath.4b",
"sokal.sneath.5a",
"sokal.sneath.5b",
"sorgenfrei",
"square.euclidean",
"stiles",
"tanimoto",
"tarantula",
"tarwid",
"three.w.jaccard",
"vari",
"yuleq.1",
"yule.2",
"yulew")
retorno$nomes_funcoes = names_function
retorno$tamanho = length(names_function)
return(retorno)
gc()
}
Essa função apenas lista e retorna o nome de todas as funções de medidas de similaridades existentes no nosso projeto. Quando a chamamos:
nomes.funcoes = getNamesListFunctions()
O retorno é:
nomes.funcoes$nomes_funcoes
nomes.funcoes$tamanho
Se fizermos o seguinte:
nomes.funcoes$nomes_funcoes[1]
Obteremos o valor:
[1] "ample"
Dessa forma, podemos fazer um LOOP para percorrer esse vetor de nomes de funções e executar todas elas. Como eu só quero para quatro dessas medidas, e também quero demonstrar que as duas funções de cálculo funcionam, então vou criar dois vetores separados considerando os nomes das funções criadas.
funcoes.sim.1 = c("cosine.v1", "jaccard.v1", "russel.rao.v1", "vari.v1")
funcoes.sim.2 = c("cosine.v2", "jaccard.v2", "russel.rao.v2", "vari.v2")
Se você colocar ali um nome de função que não existe, vai dar erro! Em seguida, criarei duas variáveis do tipo lista para armazenar os resultados das quatro medidas para as duas versões de funções:
resultado.v1 = list()
resultado.v2 = list()
As matrizes resultantes ficarão guardadas nessas variáveis. Agora vem o LOOP:
s = 1
while(s<=length(funcoes.sim.1)){
cat("\n", funcoes.sim.1[s])
ma = calcula.tabela.contingencia(dataset, ncol(dataset), calcula.a)
mb = calcula.tabela.contingencia(dataset, ncol(dataset), calcula.b)
mc = calcula.tabela.contingencia(dataset, ncol(dataset), calcula.c)
md = calcula.tabela.contingencia(dataset, ncol(dataset), calcula.d)
resultado.v1[[s]] = data.frame(calcula.medida.v1(dataset, ncol(dataset),
ma$tabela.contingencia,
mb$tabela.contingencia,
mc$tabela.contingencia,
md$tabela.contingencia,
mn$mn,
eval(parse(text=funcoes.sim.1[s]))))
resultado.v2[[s]] = data.frame(calcula.medida.v2(eval(parse(text=funcoes.sim.2[s])),
a = as.matrix(ma$tabela.contingencia),
b = as.matrix(mb$tabela.contingencia),
c = as.matrix(mc$tabela.contingencia),
d = as.matrix(md$tabela.contingencia)))resultado.v1[[s]] = resultado.v1[[s]] %>% mutate_all(function(x) ifelse(is.infinite(x), 0, x))
resultado.v2[[s]] = resultado.v2[[s]] %>% mutate_all(function(x) ifelse(is.infinite(x), 0, x))
s = s + 1
gc()
}
length(funcoes.sim.1) retorna o tamanho do vetor. Em nosso caso, ambos os vetores têm tamanho quatro pois estamos trabalhando com quatro funções de similaridades e que estão nomeadas dentro do vetor. Portanto, enquanto s for menor que 4, o LOOP será executado. A partir do momento que s for maior que 4, o LOOP para sua execução.
O que está dentro do LOOP vocês já conhecem e, portanto, não vou explicar novamente, basta consultar os artigos anteriores se houver alguma dúvida. O que definitivamente muda aqui em relação a todo o resto que já estudamos, é a passagem dos vetores funcoes.sim.1 e funcoes.sim.2 como parâmetros.
A primeira vez que o LOOP executar, será executada a função da primeira posição do vetor que é cosine. Na segunda posição, o jaccard, na terceira posição e passagem, a russel.rao, e, por último, a vari. Portanto, as funções das medidas de similaridade serão executadas na ordem do vetor, uma de cada vez. Tem outra coisa diferente aí também, vejam:
eval(parse(text=funcoes.sim.1[s]))
eval(parse(text=funcoes.sim.2[s]))
O que esse trechinho de código faz? Bom, parse vem de conversão, então nesta parte aqui parse(text=funcoes.sim.1[s]) estamos convertendo uma string, um texto, para um elemento, expressão ou chamada R. eval() avalia uma expressão passada como parâmetro e, em nosso caso, queremos que essa expressão seja a nossa string transformada em código.
A explicação sobre é ainda um pouco mais complexa, mas não há espaço aqui para aprofundar nesse tópico em particular. O que é importante vocês entenderem agora é que, a partir de eval(parse()), podemos transformar os nomes das funções dentro do nosso vetor, no nome da chamada da função propriamente dita que queremos. Se fizermos o seguinte:
s=1
funcoes.sim.1[s]
eval(parse(text=funcoes.sim.1[s]))
funcoes.sim.2[s]
eval(parse(text=funcoes.sim.2[s]))
Veja o que acontece ao executarmos esse trechinho de código:
> s=1
> funcoes.sim.1[s]
[1] "cosine.v1"
> eval(parse(text=funcoes.sim.1[s]))
function(a,b,c,d,n){
return(a/((sqrt(abs((a+b)*(a+c))))^2))
}
<bytecode: 0x55b49a6e23c8>
> funcoes.sim.2[s]
[1] "cosine.v2"> eval(parse(text=funcoes.sim.2[s]))
function(l){
return(l$a/sqrt(abs((((l$a+l$b)*(l$a+l$c))))^2))
}
<bytecode: 0x55b49f09b410>
Como vocês podem notar, eval está retornando para nós a função propriamente dita. É assim que conseguimos fazer com que a função seja executada dentro das outras funções a partir da passagem do vetor de string como parâmetro. O resultado da execução é:
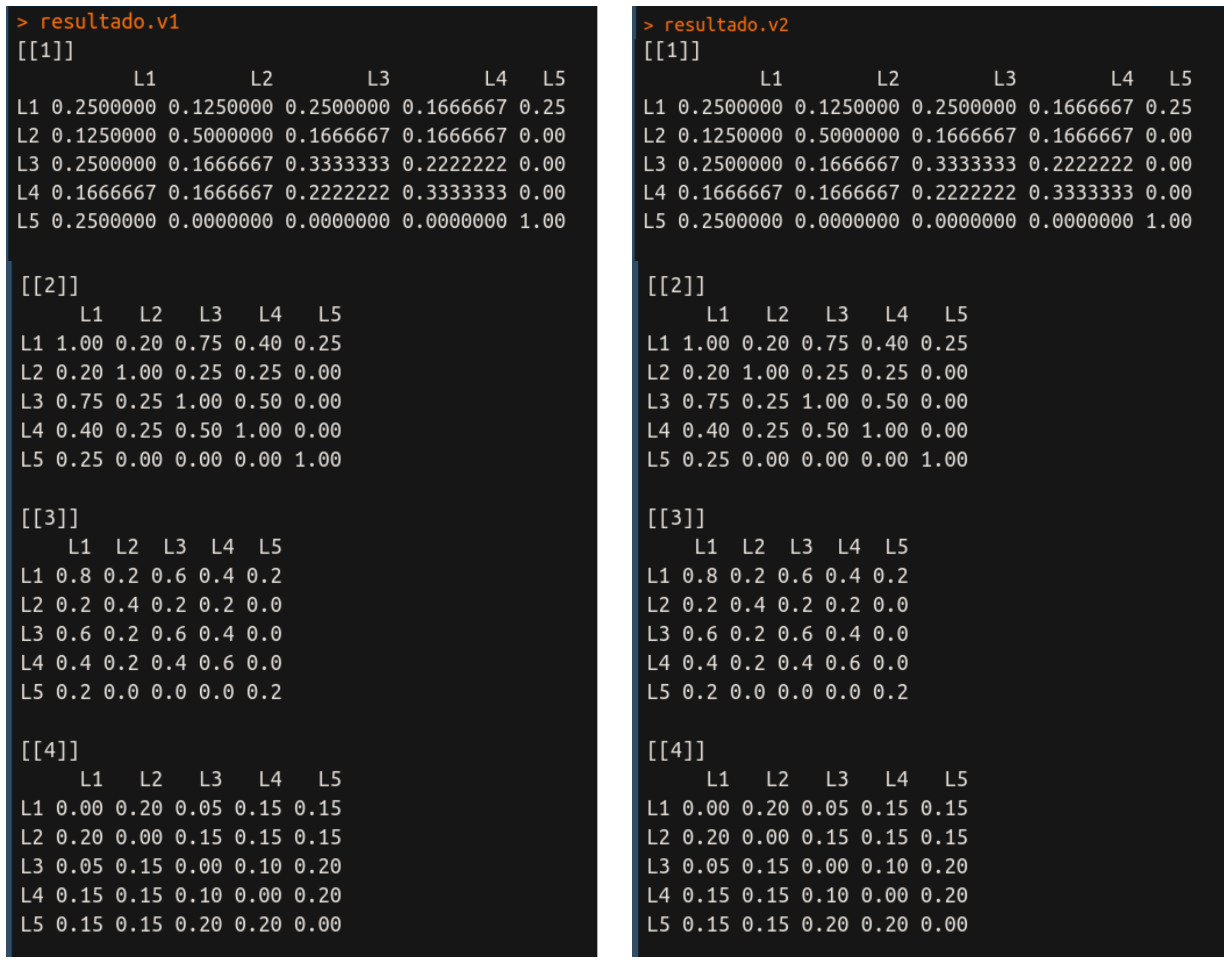
Vejam, os resultados são idênticos para ambas as funções, então você pode escolher qual você prefere usar. No retorno não aparece os nomes cosine, jaccard, etc, apenas os números, que indicam ali a ordem. Mas para nossa alegria tem como mudar, basta fazermos o seguinte:
funcoes.sim = c("cosine", "jaccard", "russel.rao", "vari")
names(resultado.v1) <- funcoes.sim
names(resultado.v2) <- funcoes.sim
names() nos permite dar nomes à nossa lista! Assim eu, primeiro, criei um vetor com os nomes das medidas e, em seguida, o atribui às duas listas de resultados. Agora você pode acessar os itens da lista pelos nomes:
resultado.v1$cosine
resultado.v1$jaccard
resultado.v1$russel.rao
resultado.v1$variresultado.v2$cosine
resultado.v2$jaccard
resultado.v2$russel.rao
resultado.v2$vari
Muito legal, né?! Por hoje é só tudo isso galera!!!! No próximo artigo finalizarei essa série, mostrando como vocês podem executar tudo isso usando paralelismo, isto é, como você pode executar vários cálculos ao mesmo tempo. Nos vemos lá.
Este artigo foi escrito por Elaine Cecília Gatto - Cissa e publicado originalmente em Prensa.li.