


Classificação Multirrótulo: Propriedades dos Dados Multirrótulo - Parte 1


Oi, gente! Vamos começar uma nova série dentro do tópico Classificação Multirrótulo, que é a área que eu estou trabalhando no meu doutorado. Nós já falamos sobre as Medidas de Avaliação e Medidas de Similaridades com detalhes. Agora é a vez de entendermos, com um pouco mais de detalhes, os dados multirrótulo. Vamos lá, então!
Onde encontrar dados multirrótulo?
Existem dois lugares que eu recomendo para obter conjuntos de dados multirrótulo tradicionais para usar em experimentos:
Em ambos é possível fazer o download dos datasets originais ou então estratificados, isto é, divididos em treino e teste, ou treino/teste/validação, ou ainda em X-Folds Cross-Validation.
Nesta série, vou utilizar o dataset FLAGS por ter poucas instâncias e rótulos e, assim, fica mais fácil demonstrar os cálculos que faremos. O dataset foi baixado do repositório cometa, sugiro que vocês usem exatamente o mesmo arquivo que estarei usando aqui.
Criando o projeto no RStudio
A partir de agora, em todos os meus artigos, farei uso de projetos no RStudio para facilitar a demonstração. Caso você não saiba nada sobre programação, sobre R, sobre RStudio, etc., não se preocupe, vou cobrir aqui o essencial para você poder acompanhar a série.
Caso não tenha o R e o RStudio instalados em seu computador, sugiro fazer isso antes de começar. Você pode seguir os tutoriais a seguir para isto:
Depois que estiver com ambos instalados, entre no RStudio e vá em ARQUIVO e, então, CRIAR NOVO PROJETO. Escolha NOVO DIRETÓRIO, em seguida NOVO PROJETO, e dê o nome "Propriedades-Multirrotulo". Nunca use acentos e espaços em nomes de projetos.
Feito isto, vamos criar, dentro do projeto, uma pasta chamada R e outra chamada Dados. Veja a Figura:
Legal! Agora dentro da pasta R vamos salvar todos os nossos scripts R e dentro de Dados vamos colocar o dataset FLAGS.
Download do Dataset
Para fazer download do arquivo no site do cometa, acompanhe as imagens a seguir:


Formato de arquivo
A maioria dos datasets são salvos no formato ARFF. Vá até a pasta DADOS e abra o arquivo flags.arff em um editor de texto simples como Notepad, ou Notepad++. Você verá o seguinte:
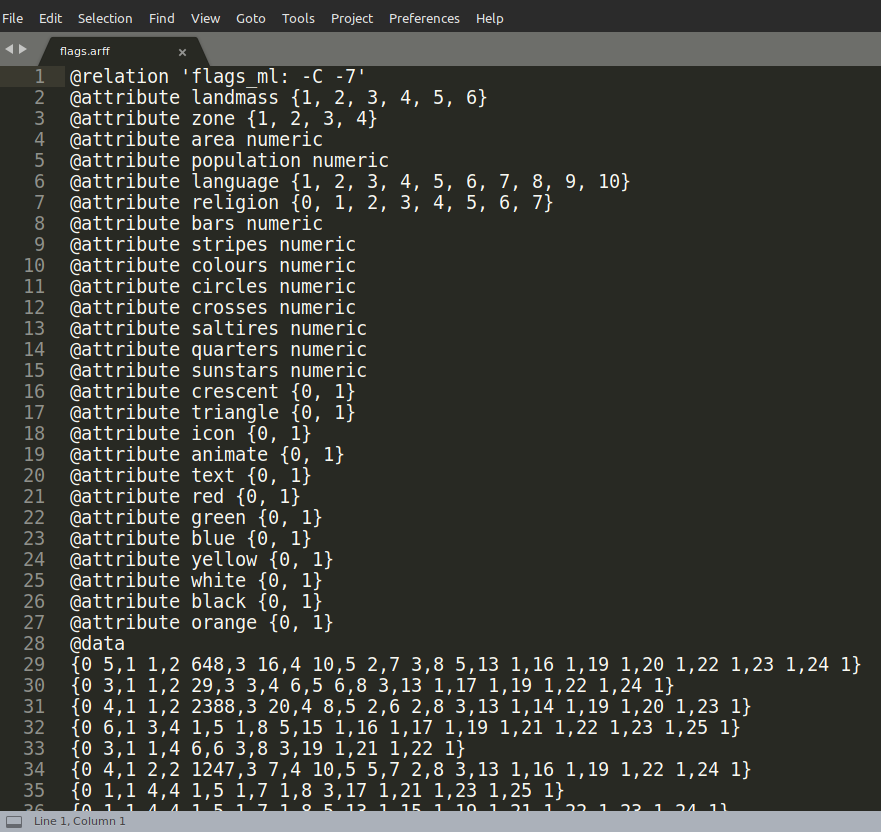
Note que as primeiras linhas do arquivo têm o seguinte formato:
@attribute + nome do atributo + tipo do atributo
@attribute significa atributo. O que vem em seguida é o nome do atributo propriamente dito, isto é, o nome da coluna do dataset. Por último vem o tipo desse atributo, isto é, ele é uma string, um caracter, um número, é um valor binário? Caso esteja perdido sobre o que é atributo, sugiro você ler (ou reler) estes artigos aqui antes de continuar:
Após o @attribute temos @data, que corresponde à seção dos dados propriamente ditos. Portanto, um arquivo de formato ARFF, primeiro define os nomes e tipos dos atributos dos dados, e os dados de fato vêm depois disso. Essa é uma das várias formas de se organizar um arquivo de dados.
O arquivo flags.xml contém informações dos rótulos do dataset. Você também pode abri-lo usando o Notepad e verá o seguinte:

A primeira linha desse arquivo, basicamente, indica a versão do xml e a codificação de texto utilizada (utf-8 é padrão). Em seguida, tem uma tag chamada labels e, depois, vêm as tags com os nomes dos rótulos propriamente ditos.
Portanto, nosso arquivo ARFF contém todos os atributos e dados, e o arquivo XML indica quem, entre esses atributos, são os rótulos. Você precisa desses dois arquivos para poder manipular o dataset, ok? Por isso, os dois devem estar na mesma pasta e ter o mesmo nome.
Pra mim, esta é uma forma horrível de visualizar os dados e, por isto, nós vamos abrir este arquivo em um formato de tabela em nosso projeto, que é muito mais fácil de ver! Por favor, lembre-se de fechar os arquivos antes de continuar com a leitura.
Estruturando os scripts R
Bom, agora que já demos uma olhada nos dados, vamos estruturar os scripts para nosso projeto:

Por hora, nós vamos criar três scripts R:
bibliotecas.R: aqui vamos adicionar todos os pacotes que usaremos;
propriedades.R: aqui vão as funções para cálculo das propriedades;
principal.R: este é o programa principal, onde vamos chamar as funções dos outros scripts.
Para criar estes scripts, vá no seu projeto, clique no menu ARQUIVO, em seguida clique em CRIAR NOVO SCRIPT R e, por fim, salve-o com o nome do script. Você criará três novos scripts e dará os respectivos nomes a eles na hora de salvar. Lembre que eles devem ser salvos dentro da pasta chamada R. Ficará assim:

Pronto! Agora tudo o que precisamos fazer é começar a codificar, mas é claro que não faremos isso de qualquer jeito. Conforme as propriedades multirrótulo forem sendo apresentadas, nós as vamos codificando, testando e ajustando todo o projeto.
Características dos dados Mutirrótulo
Propriedades de dados multirrótulo também podem ser chamadas de características dos dados multirrótulo. Como mencionei anteriormente, leia os artigos citados previamente para continuar a leitura. Aqui vou apenas citar as principais características e algumas delas já foram explicadas naquelas artigos.
Atributos (não precisam de cálculo)
Instâncias (não precisam de cálculo)
Rótulos (não precisam de cálculo)
Entradas (não precisam de cálculo)
Rótulos simples
Frequência e Proporção de Rótulos Simples
Combinações de Rótulos
Frequência e Proporção de Combinações de Rótulos
Rótulos Distintos
Frequência e Proporção de Rótulos Distintos
Frequência máxima
Cardinalidade
Densidade
Nível de Desbalanceamento de Rótulos
Scumble
TCS
etc.
Concluindo
Bom, temos muito assunto para tratar. A partir dos próximos artigos vamos ver como calcular as propriedades dos datasets. Espero vocês lá!
Este artigo foi escrito por Elaine Cecília Gatto - Cissa e publicado originalmente em Prensa.li.