


Classificação Multirrótulo: Propriedades dos Dados Multirrótulo - Parte 3


Olá pessoal! Estou de volta com mais conteúdos e aprendizados, para vocês e para mim também pois sempre que eu escrevo um artigo, eu aprendo muito!!! Partiu se aventurar?
Download
Antes de começarmos, que tal fazer download do projeto aqui?
Propriedades
Vamos retomar algumas propriedades que vimos no artigo passado:
Número total de instâncias
Podemos obter esta propriedade usando nrow(dataframe) que retorna o número total de linhas do dataframe. As linhas correspondem às instâncias.
Número total de atributos
Podemos obter esta propriedade usando ncol(dataframe) que retorna o número total de linhas do dataframe. As colunas correspondem aos atributos.

Número total de rótulos
Para obter esta informação de forma exata, é sempre bom consultar o artigo científico que originou o dataset, principalmente em se tratando de dados tradicionais, ou como são chamados, benchmarks datasets.
Frequência de um rótulo
Vamos entender melhor o que quer dizer isso aqui. Marcamos com o valor 1 quando uma instância pertence a um rótulo, e com o valor 0 quando ela não pertence.
Se somarmos os "1's" vamos obter o total de instâncias que pertencem àquele rótulo e, consequentemente, saberemos quantas vezes aquele rótulo em particular aparece sozinho no dataset. A essas instâncias damos o nome de instâncias positivas: "a instância X é positiva para o rótulo L".
Se somarmos os "0's" obteremos o total de instâncias que NÃO pertencem àquele rótulo, portanto, saberemos o total de instâncias negativas: "a instância X é negativa para o rótulo L". E, assim, conseguimos obter a frequência básica dos rótulos.
Quando usamos o comando soma = data.frame(apply(labels2, 2, sum)) a gente obtém a soma dos 1s, mas, e para somar os 0s? Pra isso, devemos usar outro comando:
frequency = data.frame(apply(labels, 2 , table))
Passamos TABLE como terceiro parâmetro em APPLY e, com isso, conseguimos obter as frequências de 0s e 1s para todos as colunas, que são os nossos rótulos:
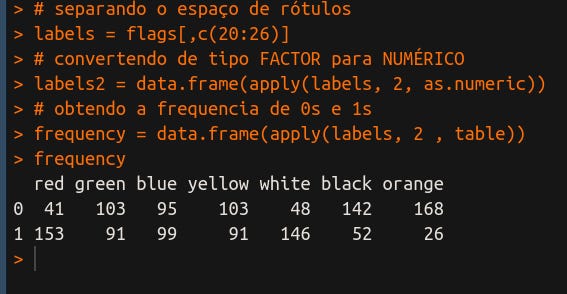
Agora sim! Vejamos: aparece o zero e o um ali como nome da linha e, então, em cada coluna temos os valores correspondentes. O rótulo ORANGE, por exemplo, tem poucas instâncias positivas e isso pode ser um problema na hora do aprendizado do algoritmo. Como ele será capaz de aprender um rótulo que é pouco frequente?
Aqui entra uma questão que eu já introduzi neste artigo, que é o desbalanceamento de classes (rótulos). Quando há muita diferença nessa frequência, o algoritmo de aprendizado de máquina pode não aprender corretamente, ou aprender muito uma coisa e pouco outra coisa. Existe uma área só para estudar como resolver este problema! Legal, né?
Frequência de pares de rótulo
E se quisermos saber a frequência com que cada par de rótulos aparece conjuntamente no dataset? Por exemplo, eu quero saber quantas vezes o rótulo RED aparece junto com o rótulo ORANGE, e assim por diante. Bom, daí a gente precisa calcular a coocorrência entre os pares de rótulos.
Se você ainda não abriu o projeto no Rstudio, então abra-o e vá no script teste que estamos usando. Lá no final, execute o seguinte comando:
labels$red == 1
A resposta pra isso vai ser algo parecido com:

Agora faça:
labels$red==0

O comando labels$red==1 verifica se o conteúdo da coluna especificada (rótulo red) é igual ao valor que designamos ali (1), retornando TRUE para quando é verdade, e FALSE caso contrário. O mesmo acontece com o comando labels$red==0, só que agora a avaliação é se o conteúdo é igual a zero. Legal, aprendemos a fazer uma comparação de uma forma direta!
Agora o que quero fazer é contar quantas vezes o rótulo RED é igual a 1 e o rótulo ORANGE também. Essa é a forma que sabemos que eles ocorrem juntos no dataset. Também podemos entender isso como o total de instâncias que foram associadas a esses dois rótulos ao mesmo tempo.
Nós podemos usar o operador lógico E para verificar isso. Esse operador, quando aplicado, retorna TRUE para todos os casos em que for verdadeiro que o operando do lado esquerdo seja igual ao operando do lado direito. Em nosso caso, o comando fica assim:
labels$red==1 & labels$orange==1
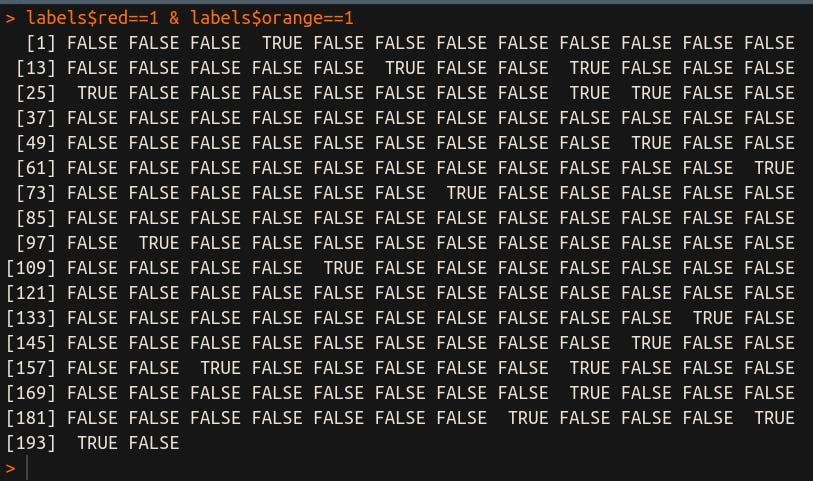
Tá, legal, interessante isso aí, mas eu quero saber o total e não esse monte de TRUE/FALSE que deixa meus olhos doendo! Concordo contigo! Daí que podemos usar o comando COUNT para contar a frequência, da seguinte forma:
count(labels, (labels$red==1 & labels$orange==1), name = "frequency")

Opa! Agora sim! Está mais próximo do que queremos. Quer tirar a prova? Vamos abrir esse arquivo no EXCEL. Para isso, primeiro termos de salvar o dataset no formato csv. Execute os seguintes comandos:
setwd(FolderDados)
write.csv(labels, "rotulos-flags.csv", row.names = FALSE)

Agora, vá na sua pasta DADOS dentro do projeto do RStudio e abra o arquivo "rotulos-flags.csv" no Excel ou Libre Office.

Agora, selecione todas as linhas e colunas e vá em ordenação. Lá vamos primeiro ordenar por RED e depois por ORANGE na ordem decrescente.

Em seguida, vou aplicar uma cor nas linhas em que tanto RED quanto ORANGE tem o valor 1 e colocar ali do ladinho um contador, vejam como ficou:

Óh!!!!! Realmente, os rótulos RED e ORANGE aparecem juntos apenas 19 vezes. Isso significa que nosso comando no R está correto. Agora, voltando aos pares, quantas combinações de pares de rótulos temos no dataset flags? Para sabermos isso, basta fazer 7 rótulos x 7 rótulos, portanto, 49 combinações. A Figura a seguir ilustra isto:

Uau! Realmente são muitas! Mas, olha, eu acho que podemos tirar algumas da jogada. Por exemplo, RED com RED não é necessário, nem GREEN com GREEN, portanto, a frequência do rótulo com ele mesmo não é necessária. Assim temos 49-7 = 42 combinações.
Além disso, a gente também pode notar que há pares repetidos! Exemplo: GREEN e RED é o mesmo que RED e GREEN - a ordem não fará diferença aqui. Com isso ficamos com os seguintes pares:

De 49 fomos para 21 combinações, bem menos da metade! Bom, ainda assim são várias combinações que precisamos verificar. Tem algum jeito de fazer isso automaticamente, sem precisar ficar escrevendo uma linha de código pra cada combinação? E se eu te falar que tem?!
A forma de se fazer isso é um tanto mais elaborada do que eu já mostrei até agora. Portanto, para não ficar muito extenso e complicado, vou finalizando este artigo por aqui.
FINALIZANDO
Pessoal, espero que tenham gostado do conteúdo até aqui. Se tiverem dúvidas, por favor, me mandem mensagem no meu Linkedin. Aguardo vocês no próximo artigo.
Este artigo foi escrito por Elaine Cecília Gatto - Cissa e publicado originalmente em Prensa.li.