


Classificação Multirrótulo: Propriedades dos Dados Multirrótulo - Parte 7


Oi, gente!!! Tô de volta aqui com mais conteúdos para vocês. Neste artigo terminaremos de estudar as propriedades dos dados multirrótulo. Vamos lá então?
DOWNLOAD
Antes de começar, faça download do projeto do RStudio, clicando aqui! Abra o projeto em seu computador e não esqueça de verificar se todos os pacotes necessários estão instalados. Eles estão listados no arquivo bibliotecas.R, o qual você deve executar antes de continuar com a leitura deste artigo. Caso tenha dúvidas no processo, você pode entrar em contato comigo nas minhas redes sociais.
DESBALANCEAMENTO
Outra propriedade importante para calcularmos é o desbalanceamento de classes: quando o número total de rótulos do espaço de rótulos é muito alto, é possível que o número de instâncias positivas para determinados rótulos seja bem pequeno e o número de instâncias negativas alto, assim como alguns rótulos podem ser mais frequentes que outros.
Pode também haver um número alto de instâncias associadas a conjuntos de rótulos frequentes e, também, um alto número de instâncias associadas a conjuntos de rótulos menos frequentes, o que é conhecido como label skew.
Se o dataset tiver um alto desbalanceamento, o aprendizado também será difícil para o algoritmo. Por exemplo, um rótulo que aparece pouquíssimas vezes é considerado raro e, com poucas instâncias pertencendo a ele, é possível que o algoritmo nem aprenda esse rótulo!
REVISITANDO O CÓDIGO
Antes de continuar vamos revisitar o nosso código até agora, que está todo em teste.R. Primeiro, definimos algumas pastas que iremos manipular:
FolderRoot = "~/Propriedades-Multirrotulo"
FolderScripts = "~/Propriedades-Multirrotulo/R"
FolderDados = "~/Propriedades-Multirrotulo/Dados"
Depois, carregamos os pacotes que iremos utilizar:
setwd(FolderScripts)
source("bibliotecas.R")
Em seguida, abrimos o dataset:
nome.arff = paste(FolderDados, "/flags.arff", sep="")
flags = data.frame(read.arff(nome.arff))
Depois, separamos o espaço de rótulos:
labels = data.frame(flags[,c(20:26)])
E então, transformamos os dados categóricos do espaço de rótulos em numéricos:
labels.2 = data.frame(apply(labels, 2, as.numeric))
A partir daí, começamos a fazer a análise do dataset e descobrir suas propriedades. Primeiro o número total de instâncias e atributos
nrow(flags)
ncol(flags)
Obtemos a frequência de instâncias positivas e negativas para cada rótulo:
frequency = data.frame(apply(labels.2, 2 , table))
Daí calculamos a co-ocorrência de pares de rótulos:
resultado = map_dfr(.x = combn(names(labels), 2, simplify = FALSE),
~ labels %>%
select(.x) %>%
summarise(par_a = .x[1],
par_b = .x[2],
n = sum(rowSums(select(., everything()) == 1) == 2)))
Calculamos a cardinalidade:
card = mean(rowSums(labels.2))
Calculamos a densidade:
dens = mean(rowSums(labels.2))/ncol(labels.2)
Descobrimos quais são as combinações de rótulos existentes no espaço de rótulos:
labelsets <- do.call(paste, c(labels, sep = ""))
labelsets <- table(as.factor(labelsets))
labelsets <- data.frame(labelsets)
names(labelsets) = c("combinacao", "frequencia")
labelsets = arrange(labelsets, frequencia)
Também descobrimos as combinações de rótulos únicas:
labels.sets.unique = filter(labelsets, labelsets$frequencia==1)
E calculamos o total dessas combinações:
num.total.comb = nrow(labelsets)
num.total.comb.unique = nrow(labels.sets.unique)
Descobrimos, também, quais são as frequências máxima e mínima de combinações de rótulos, excluindo as únicas:
labels.sets = arrange(labelsets, frequencia)
labels.sets = filter(labels.sets, labels.sets$frequencia!=1)
label.set.freq.max = max(labels.sets$frequencia)
label.set.freq.min = min(labels.sets$frequencia)
Identificamos o total de ocorrências para as combinações de rótulos
unique = labels.2 %>% mutate(total = rowSums(labels.2))
unique = arrange(unique, total)
frequencia = data.frame(count(unique, total))
names(frequencia) = c("total", "frequencia")
E agora nós vamos calcular o desbalanceamento!
CALCULANDO O DESBALANCEAMENTO
Vamos fazer essa conta no passo a passo. Primeiro, vamos executar o seguinte comando: label.count = colSums(labels.2). Esse comando vai somar as colunas do espaço de rótulos:

Essa informação a gente meio que já sabia, né? Mas vamos continuar. O próximo passo é calcular a frequência com o comando: label.freq = label.count / nrow(labels.2)
Agora, calculamos uma coisa chamada IRBL, que é o nível de desbalanceamento de um rótulo específico: IRLbl = max(label.count) / label.count

Vejam que essa continha consiste de pegar o valor máximo do label.count e dividir por ele! Em nosso caso, o valor máximo de label.count é 153 e, por isso, o rótulo red tem o valor 1.0!
Um valor de IRLbl igual a 1 indica rótulos com maior frequência, enquanto que um valor maior que 1 indica rótulos menos frequentes. Portanto, quanto maior o valor de IRLbl, mais rara é a presença do rótulo em D.
Podemos notar então que o rótulo orange é o menos frequente, portanto, o mais raro. Agora calculamos a média do desbalanceamento: meanIR = mean(IRLbl)
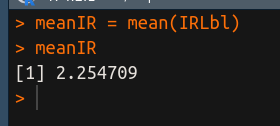
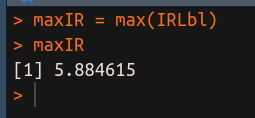
Se o valor de IRLbl for alto para muitos rótulos, ou se o nível de desbalanceamento for extremo para alguns rótulos, então o valor de MeanIR é alto. Vamos calcular, também, o valor máximo do desbalanceamento: maxIR = max(IRLbl). O objetivo da métrica MaxIR é obter a razão de desbalanceamento máximo, em outras palavras, a proporção do rótulo mais comum em relação ao mais raro.
TCS
TCS é uma medida que calcula o produto do número de atributos, número de rótulos e número de combinações diferentes de rótulos. O valor retornado por TCS indica a dificuldade em aprender um modelo preditivo do conjunto de dados: quanto mais alto o valor, mais difícil é o aprendizado. Na equação, Ls indica o número total de combinações de rótulos.
TCS(D) = log(m × n × Ls)
Podemos usar o seguinte comando para calcular o TCS:
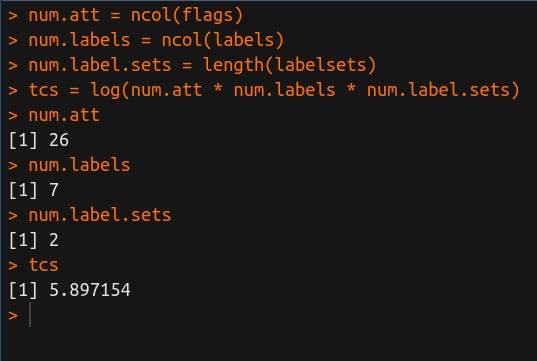
num.att = ncol(flags)
num.labels = ncol(labels)
num.label.sets = length(labelsets)
tcs = log(num.att * num.labels * num.label.sets)
FINALIZANDO
E, assim, terminamos de estudar as propriedades dos dados multirrótulo. O que nos resta agora é ajustar o código no projeto R! Para não ficar confuso, vou deixar esta parte para outro artigo! Espero que você tenha tido uma ótima leitura! Nos vemos no próximo artigo.
Este artigo foi escrito por Elaine Cecília Gatto - Cissa e publicado originalmente em Prensa.li.