


Classificação Multirrótulo: Propriedades dos Dados Multirrótulo - Parte 8 (Final)

")
Oi, galera! Vamos terminar hoje a nossa série sobre propriedades dos dados multirrótulo! Foi uma série mais tranquila e curta com relação à anterior, porém tão enriquecedora quanto. Vamos lá, então?
ORGANIZANDO O CÓDIGO
Como mencionei no artigo passado, neste artigo aqui vamos ajeitar o código no projeto do RStudio. Fizemos nossos testes em um script chamado teste.R e agora nós vamos pegar o que está lá e colocar em seu devido lugar.
Script bibliotecas.R
Neste script vamos colocar apenas os pacotes R que usamos em nosso código. Ele ficará assim:
FolderRoot = "~/Propriedades-Multirrotulo"
FolderScripts = "~/Propriedades-Multirrotulo/R"library(tidyverse)
library(foreign)
library(magrittr)
Script propriedades.R
Neste script vamos colocar uma função que vai calcular todas as propriedades dos dados multirrótulo. Não precisamos criar uma função diferente para cada propriedade, mas se você quiser você pode.
Como essas propriedades retornam um valor simples, é interessante criarmos uma função que retorne todos esses valores de uma vez só. Além disso, o tempo de execução não é demorado, então, vale a pena fazer desta forma. Veja como fica:
calcula.propriedades <- function(dataset, rotulos){
retorno = list()
# convertendo de tipo FACTOR para NUMÉRICO
labels.2 = data.frame(apply(rotulos, 2, as.numeric))
# numero total de linhas = número total de instâncias
retorno$num.instancias = nrow(flags)
# número total de colunas = número total de atributos
retorno$num.atributos = ncol(flags)
# frequencia dos rótulos
# total de instâncias positivas e negativas por rótulo
retorno$inst.neg.pos = data.frame(apply(labels.2, 2 , table))
# coocorrencia de pares de rótulos
freq.pares.rotulos = map_dfr(.x = combn(names(rotulos), 2, simplify = FALSE),
~ rotulos %>%
select(.x) %>%
summarise(par_a = .x[1],
par_b = .x[2],
n = sum(rowSums(select(., everything()) == 1) == 2)))
names(freq.pares.rotulos)[3] = "coocorrencia"
retorno$freq.pares.rotulos = arrange(freq.pares.rotulos, desc(coocorrencia))
# cardinalidade
retorno$cardinalidade = mean(rowSums(labels.2))
# densidade
retorno$densidade = mean(rowSums(labels.2))/ncol(labels.2)
# combinações de rótulos
labelsets <- do.call(paste, c(rotulos, sep = ""))
labelsets <- table(as.factor(labelsets))
labelsets <- data.frame(labelsets)
names(labelsets) = c("combinacao", "frequencia")
retorno$labelsets = arrange(labelsets, frequencia)
# total de combinações
retorno$total.combinacoes = nrow(labelsets)
# combinações únicas
labels.sets.unique = filter(labelsets, labelsets$frequencia==1)
# total de comibinações únicas
retorno$total.comb.unicas = nrow(labels.sets.unique)
# combinações não únicas
labels.sets = arrange(labelsets, frequencia)
labels.sets = filter(labels.sets, labels.sets$frequencia!=1)
retorno$total.comb.nao.unicas = nrow(labels.sets)
# frequencia maxima
retorno$labelset.freq.max = max(labels.sets$frequencia)
# frequencia minima
retorno$labelset.freq.min = min(labels.sets$frequencia)
# total de instâncias atribuídas a X rótulos
unique = labels.2 %>% mutate(total = rowSums(labels.2))
unique = arrange(unique, total)
frequencia = data.frame(count(unique, total))
names(frequencia) = c("total", "frequencia")
# total de instâncias atribuidas a um único rótulo
inst.rotulo.unico = filter(frequencia, frequencia==1)
retorno$inst.rotulo.unico = inst.rotulo.unico$frequencia
#
retorno$freq.rot.inst = frequencia
# DESBALANCEAMENTO
# conta as colunas
label.count = colSums(labels.2)
# frequencia
label.freq = label.count / nrow(labels.2)
# desbalanceamento
IRLbl = max(label.count) / label.count
retorno$IRLbl = IRLbl
# média do desbalanceamento
retorno$meanIR = mean(IRLbl)
# maximo IR
retorno$maxIR = max(IRLbl)
# tcs
retorno$tcs = log(abs(ncol(flags) * ncol(labels.2) * nrow(labelsets)))
return(retorno)
gc()
}
Notem que eu criei uma variável chamada retorno e que é do tipo list. Isso significa que retorno vai ser uma lista que conterá todos os valores calculados. Para adicionarmos um valor à lista, usamos o símbolo $ e, então, damos um nome ao valor que queremos colocar ali.
Por exemplo, usei retorno$cardinalidade = cardinalidade para armazenar o valor resultante da função cardinalidade. Também tentei usar nomes fáceis de lembrar o que é cada propriedade, mas confesso que é muito difícil dar nomes. Vocês com certeza pensarão em nomes melhores do que os meus.
Este código está todo em português brasileiro, no entanto, você pode mudar para outro idioma de sua preferência. Como aqui meu objetivo é popularizar a ciência tornando o conhecimento mais acessível a todos os públicos, então eu prefiro usar sempre a nossa língua mãe.
A função também solicita dois parâmetros: dataset, que é o próprio dataset, e labels que é apenas o espaço de rótulos. Quando você for chamar a função, você precisa passar esses parâmetros, caso contrário obterá um erro.
Note, também, que no final da função tem a linha return(retorno). Se você esquecer essa linha, a função não vai retornar nada pra quem está chamando. O cálculo será realizado, mas você não verá resultado algum em nenhum lugar.
Portanto, sempre que quiser que valores sejam retornados em uma chamada de função, você deve usar o comando return(). Se não é isso que quer, então você deve, de alguma forma, salvar e deixar disponível os cálculos/resultados.
Script principal.R
O script principal é aquele vai executar tudo. É nele que vamos chamar a função para fazer os cálculos.
# diretórios
FolderRoot = "~/Propriedades-Multirrotulo"
FolderScripts = "~/Propriedades-Multirrotulo/R"
FolderDados = "~/Propriedades-Multirrotulo/Dados"FolderResultados = "~/Propriedades-Multirrotulo/Resultados"
# carregando outros scripts
setwd(FolderScripts)
source("bibliotecas.R")setwd(FolderScripts)
source("propriedades.R")# abrindo o dataset
nome.arff = paste(FolderDados, "/flags.arff", sep="")
flags = data.frame(read.arff(nome.arff))# separando o espaço de rótulos
labels = data.frame(flags[,c(20:26)])# chama a função
res = calcula.propriedades(flags, labels)res
Primeiro, eu defino os diretórios que vou usar no projeto. Em seguida, carregamos o script bibliotecas.R e propriedades.R usando o comando source(). Esse comando nos permite carregar para outro script, um script existente. Dessa forma, as funções que estão ali naquele script podem ser usadas no outro.
O próximo passo e abrir o dataset que está armazenado na pasta dados. Usamos read.arff() pois o arquivo está salvo neste formato. Também é interessante salvar o conteúdo que foi carregado desse arquivo em um formato de dataframe.
Agora, com o dataset carregado, podemos separar o espaço de rótulos. Para saber quais colunas do dataset são os rótulos, você precisa consultar a documentação já disponível sobre ele. No site cometa você encontra essas informações bem rapidamente.
Por fim, chamamos a função para calcular as propriedades. Notem que eu passei os parâmetros necessários e estou armazenado o resultado na variável res. O resultado que obtive foi:
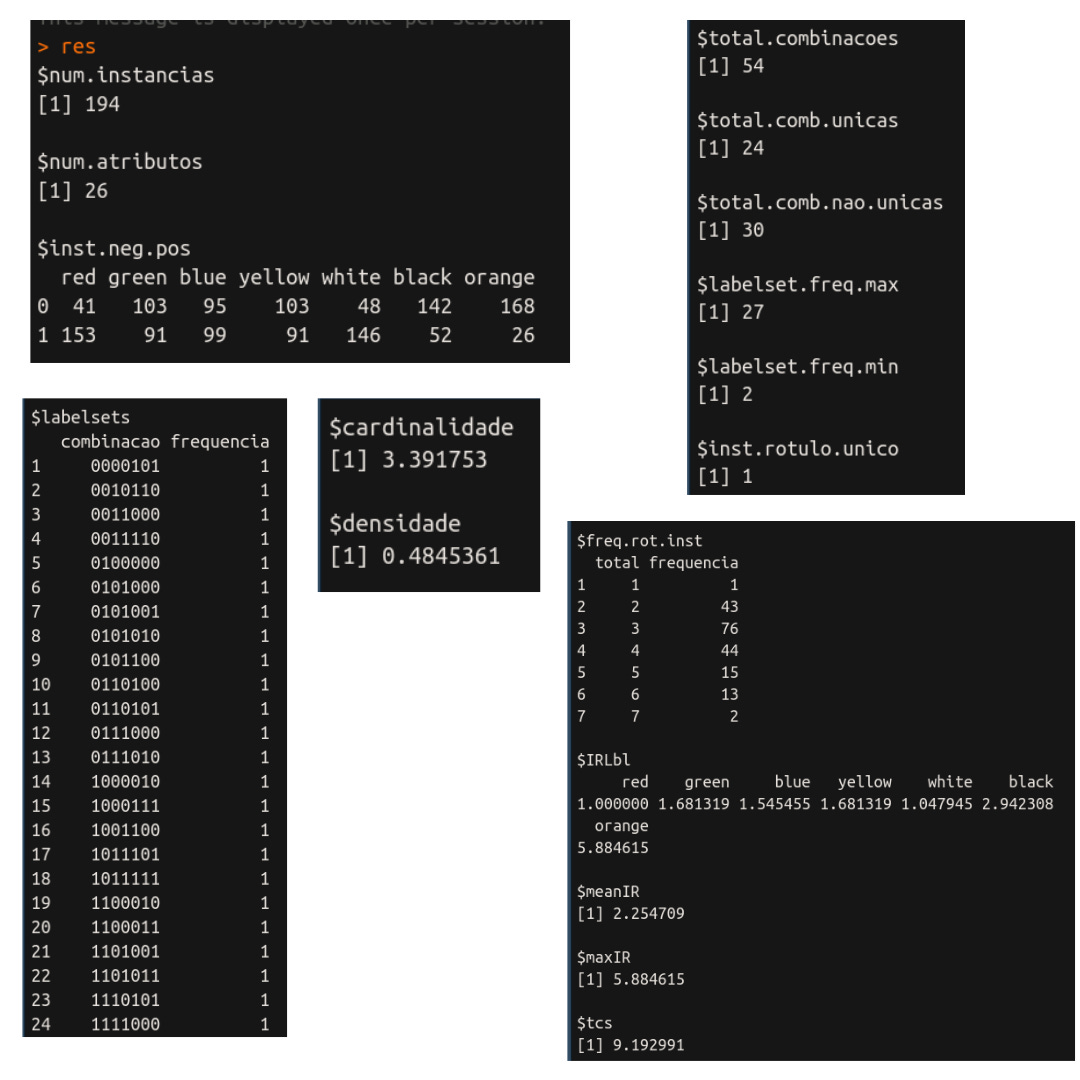
Notem que res contém todos os resultados! Se você quiser, por exemplo, calcular as propriedades para vários datasets de uma única vez, você pode! Primeiro, você deve colocar todos os arquivos .arff e .xml na pasta dados, vejam:

Agora, precisamos criar um LOOP que vai ler todos os arquivos e calcular. Ah mas antes disso, apague o arquivo rotulos-flags da pasta! Aliás, nesta pasta devem estar apenas os arquivos .xml e .arff, nenhum outro tipo deve estar ali.
Podemos usar o seguinte comando para obter os nomes dos arquivos que estão no diretório dados: nomes.arquivos = dir(FolderDados). Armazenamos o resultado em nomes.arquivos.
Para obtermos o total de arquivos que estão presentes no diretório fazemos: tamanho = length(nomes.arquivos). Mas, com isso, obteremos o valor 12, que é o dobro da quantidade de datasets, que, na verdade, são apenas 6. Então, podemos dividir esse valor por 2 para sabermos que estamos lidando com apenas 6 datasets: tamanho = length(nomes.arquivos)/2
Ótimo! Agora precisamos definir os índices das colunas dos rótulos de cada dataset pois o espaço de rótulos deve ser separado do restante. Pra facilitar eu criei aqui uma tabelinha já com essas informações e nós podemos usá-la. Faça download aqui! Essa é a cara desse arquivo datasets-info.csv:
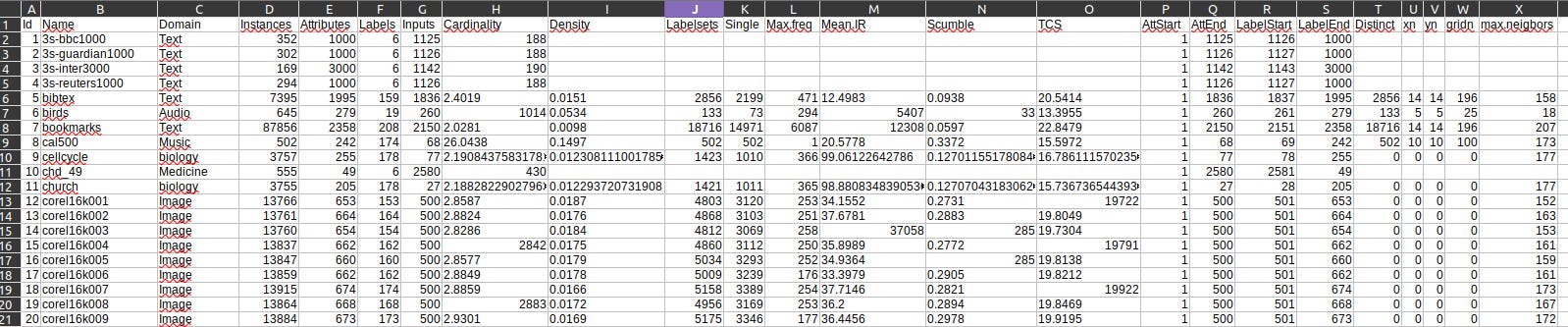
O arquivo é bem grande, então não dá para mostrar tudo aqui, porém, ele contém informações de 90 datasets multirrótulo, incluindo onde começa e onde termina o espaço de rótulos. Para abri-lo usamos os comandos
setwd(FolderRoot)
datasets = data.frame(read.csv("datasets-info.csv"))
Agora, podemos usar as informações contidas ali. Vamos usar o ID de cada dataset para criar um vetor com esses números de ID e, assim, ficar fácil encontrar as informações: indices = c(26,34,43,62,90). O LOOP vai ficar da seguinte forma:
i = 1
while(i<=tamanho){
# obtendo informação do dataset
ds = datasets[indices[i],]
cat("\n", ds$Name)# criando o nome do arquivo
nome.arff = paste(FolderDados, "/", ds$Name, ".arff", sep="")
# abrindo o dataset
multi.label.data = data.frame(read.arff(nome.arff))
# separando o espaço de rótulos
labels = data.frame(multi.label.data[,ds$LabelStart:ds$LabelEnd])
# chama a função
res = calcula.propriedades(multi.label.data, labels)
print(res)
i = i + 1
gc()
}
Aqui estou mandando imprimir o RES, mas você poderia salvá-lo em um arquivo! Ou, então, criar um dataframe para guardar todas as informações. Este é apenas um exemplo ilustrativo que pode ser aprimorado, meu objetivo era demonstrar que é possível, sim, fazer um LOOP para efetuar o cálculo das propriedades para vários datasets. Antes de encerrar, faça o download do projeto completo aqui!
CONCLUSÃO
E com isso eu encerro esta série de artigos! Espero que todos vocês tenham aprendido muito com este conteúdo. Se houver algo que considerem que deva ser melhor conduzido nas minhas séries, por favor, contatem-me nas redes sociais e me deixem saber o que é. Sou uma eterna aprendiz, uma eterna estudante e gosto de aprimorar meu trabalho. Fico mesmo muito contente por você ter chegado até aqui. Nos vemos na próxima jornada.
Este artigo foi escrito por Elaine Cecília Gatto - Cissa e publicado originalmente em Prensa.li.